こちらの記事で示したように、LASSO はラプラス事前分布を課した回帰係数の MAP 推定と見なすことができます。
まず、これを示します。ここでは、データ D=(X,y):
Xy=[x1,…,xp],xj=[x1,…,xN]⊤=[y1,…,yN]⊤
に対する線形回帰モデル
y=Xβ+ε,ε∼N(0,σ2IN)
を考えます。線形回帰モデルを構成する特徴量 xj について、一部の係数はゼロ (βj=0) であるとみなす仮定をスパース性の仮定といい、スパース性を仮定した統計モデリングを総称してスパースモデリングといいます。
Laplace 分布 Laplace(μ,b) は、以下の確率密度関数:
pμ,b(x)=2b1exp(−b∣x−μ∣)
で与えられる確率分布で、位置パラメータ μ と尺度パラメータ b を持ちます。
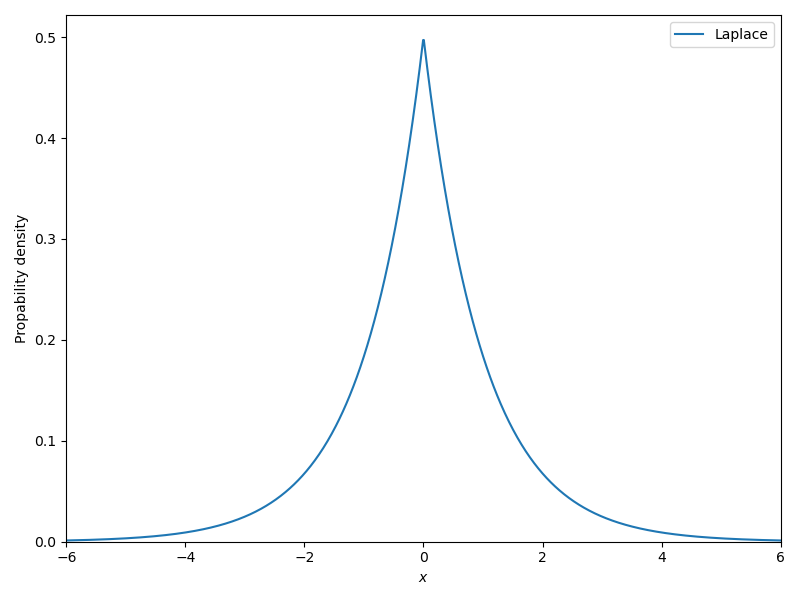
Laplace(0,1) の可視化は以下のようになります。正規分布と比べて裾が重く、ゼロの位置に不連続なピークを持つことがわかります。
コード
回帰係数 β=[β1,…,βp]⊤ の事前分布として、i.i.d な Laplace 分布:
βj∼Laplace(0,b)
を課します。確率密度関数とその対数は、
p(β)lnp(β)=2b1j=1∏pexp(−b∣βj∣)=ln2b1−j=1∑pb∣βj∣
です。ここで、線形回帰モデルの対数尤度関数は
lnp(X∣β)=−2σ21∣∣y−Xβ∣∣2−2Nln(2πσ2)
ですから、LASSO 推定量 β^LASSO は適当な λ>0 を用いた MAP 推定量として、
β^LASSO=βargmin(∣∣y−Xβ∣∣2+λ∣∣β∣∣1)
と表すことができます。ここで
∣∣β∣∣1:=j=1∑p∣βj∣
を L1-ノルムといいます。
LASSO が推定する回帰係数は MAP 推定量、すなわち事後確率が最大となるときのパラメータの値であるため、事後分布 P(β∣X) の点推定 (最頻値) となります。
これに対し、P(β∣X) そのものを推定する方法は Bayesian LASSO と呼ばれます。この場合の P(β∣X) は通常解析的でないため、Markov 連鎖モンテカルロ (MCMC) をはじめとするサンプリング法によって推定されます。
Laplace 分布は Laplace(0,b) は指数分布と正規分布の混合によって表すことができます。
Laplace 分布の階層表現
βj ∣ ττ∼N(0,τ)∼Exp(1/(2b2))
これを (やんわり) 示します。Laplace 分布の密度関数 p(βj) を指数分布のパラメータ τ で拡大すると、
p(βj)=∫0∞p(βj∣τ)p(τ) dτ
となります。正規分布と指数分布の密度関数を明示すると、
p(βj∣τ)p(τ)=2πτ1exp(−2τβj2)=2b21exp(−2b2τ)
であるので、Gauss 積分公式を使用して
pb(βj)=∫0∞2πτ1exp(−2τβj2)2b21exp(−2b2τ) dτ=2b22πτ1∫0∞exp(−2τβj2−2b2τ) dτ=2b1exp(−b∣βj∣)
となります。
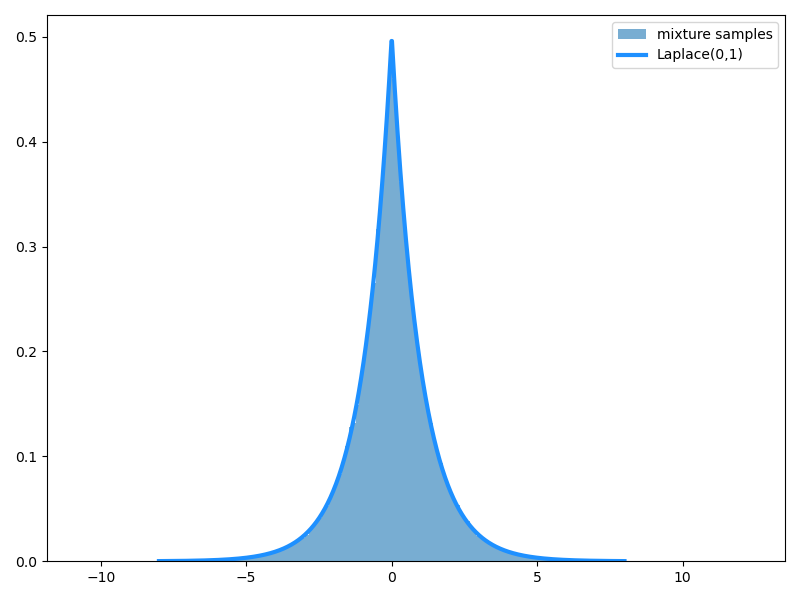
指数分布と正規分布からのサンプルで以上の階層表現を構成してみると、確かに Laplace(0,1) に近づくことがわかります。
コード
この事実を利用すれば、Bayesian LASSO を以下のように階層表現することができます。
Bayesian LASSO の階層表現
y ∣ X,β,σ2βj ∣ λj,σ2λj∼N(Xβ,σ2IN)∼N(0,σ2λj)∼Exp(τ2/2)
実際に用いる場合は、σ2,τ にも適当な事前分布をおきます (共役事前分布を用いる場合が多いのでしょうか?)。
次の問題設定を考えてみます。
yyj=β+ε,ε∼N(0,σ2IN)=βj+εj
そのような βj (j=1,…,p) の事前分布として、以下の形式の階層表現を導入します。
βj ∣ σ2,τ,λjλj∼N(0,σ2τ2λj2)∼P(⋅)
P(⋅) は適当な確率分布で、たとえば Exp とすれば Bayesian LASSO に相当します。この形式で表現できる事前分布は線形回帰モデルに βj≃0 となるような事前知識を与えます。そのような理由から、縮小事前分布と呼ばれるようです。
なお、σ2,τ,λj が所与である場合、事後分布は正規分布になります (こちらの記事↗を参照)。
σ2=1 とし、τ,λj が所与のもとで βj の事後平均は以下のようになります:
E[βj ∣ yj,τ,λj2]=1+τ2λj2τ2λj2yj
ここで、
κj:=1+τ2λj21
を縮小係数などと呼び、τ2λj2>0 であることから 0<κj<1 の範囲を取ります。事後平均を縮小係数で書き直すと、
E[βj ∣ yj,τ,λj2]=(1−κj)yj
となることから、縮小係数 κj はシグナル yj をどれくらい圧縮するかを決めるパラメータであることがわかります。また、
- τ は κ1,…,κp 全てに寄与するパラメータ
- λj は κj のみに寄与するパラメータ
であることから、τ を大域縮小パラメータ、λj を局所縮小パラメータなどと呼びます。
Laplace 分布の問題点は、任意の回帰係数 βj で縮小が起きやすくなってしまう点にあります。この問題が起きる理由は、Laplace 分布に対応する κj の事前分布を見ることで理解できます。
Laplace 分布の階層表現における局所縮小パラメータ λj に対して、
λj=κj1−κj
とすると縮小係数を定義できます。λj∼Exp(τ2/2) であるので、その確率密度関数は
pτ(λj)=2τ2exp(−2τ2λj)
と表すことができます。変数変換 λj→κj に伴う Jacobian は
∂κj∂λj=∂κj∂κj1−κj=κj21
であるので、
pτ(κj)=2κj2τ2exp(−2τ2κj1−κj)
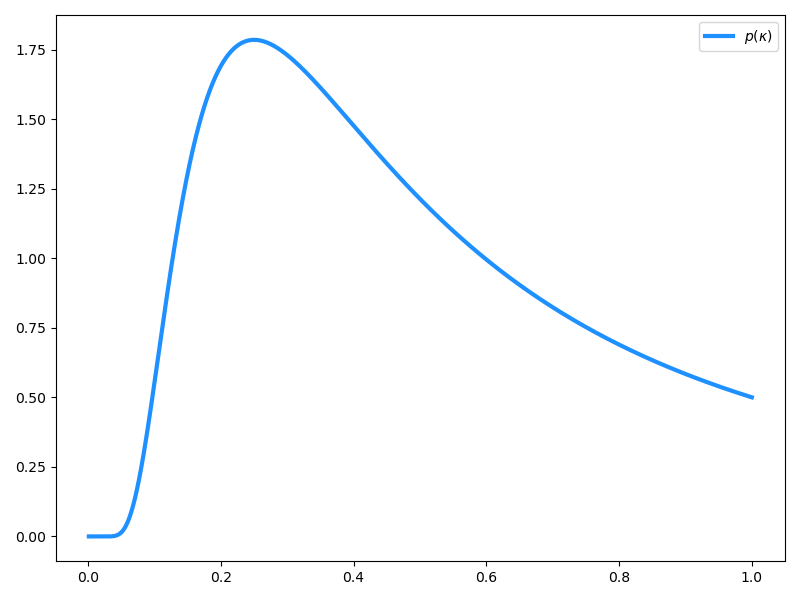
を得ます。τ=1 としてこれをプロットしたのが以下の図です。
コード
図から明らかなように、Laplace 分布は κj≃0 の近辺に密度をほとんど持たず、それゆえ多くの係数がゼロに縮退してしまいます。
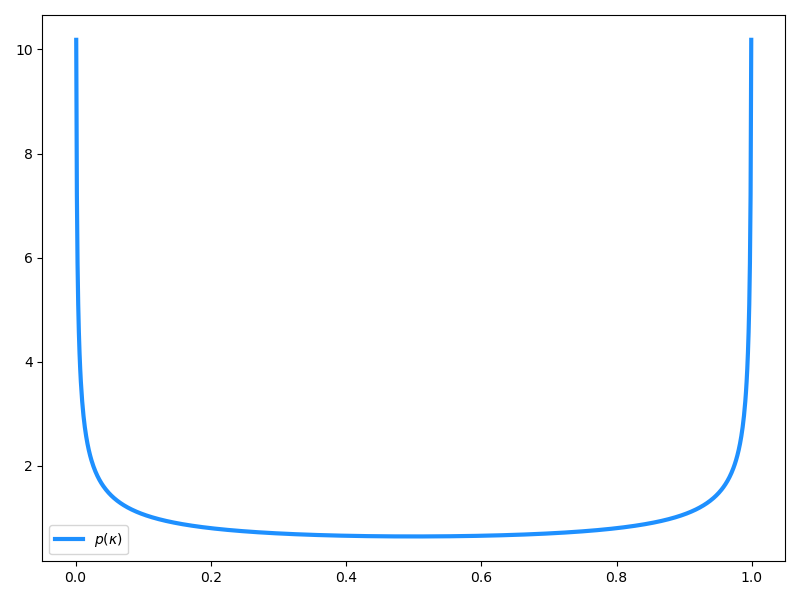
強いスパース性を担保しつつも過剰縮小を抑えるためには、κj≃0 および κj≃1 に密度を集中させれば良いことがわかります。κj の事前分布としてベータ分布 Beta(1/2,1/2) をとると、そのような性質を満足することができます。確率密度関数は以下で与えられます:
p(κj)=π1κj(1−κj)1
これをプロットしたものは以下のようになります。
コード
関数形が馬の蹄 (ひづめ) のように見えることから、これに対応する βj の事前分布は馬蹄分布と呼ばれます。局所縮小パラメータ λj と大域縮小パラメータ τ をもつ馬蹄分布は以下の階層表現で表すことができます。
馬蹄分布の階層表現
βj ∣ σ2,τ,λjτλj∼N(0,σ2τ2λj2)∼HalfCauchy(0,1)∼HalfCauchy(0,1)
HalfCauchy(0,1) は位置パラメータ 0、尺度パラメータ 1 の (標準) 半 Cauchy 分布で、確率密度関数は以下で与えられます:
p(x)={1/(π(1+x2))0(x>0)(x<0)
これを利用して、馬蹄事前分布をおいた Bayes 線形回帰を以下のような階層表現で定式化できます。
馬蹄分布による Bayes 線形回帰
y ∣ X,β,σ2βj ∣ σ2,τ,λjτλj∼N(Xβ,σ2IN)∼N(0,σ2τ2λj2)∼HalfCauchy(0,1)∼HalfCauchy(0,1)
馬蹄分布のデメリットとして、半 Cauchy 事前分布の性質上、解析的な事後分布を得にくい点が挙げられます。この問題に対処するため、解析的な事後分布を得やすい逆ガンマ分布 InvGamma(a,b) で半 Cauchy 分布を書き直すことができます。
形状パラメータ a、尺度パラメータ b を持つ逆ガンマ関数の確率密度関数は以下です:
pa,b(x)=Γ(a)baxa+11exp(−xb)
なお、Γ(t) はガンマ関数です。逆ガンマ分布を用いた半 Cauchy 分布の表現は以下のようになります。
半 Cauchy 分布の逆ガンマ表現
x∼HalfCauchy(0,γ)
にしたがう確率変数 x に対し、潜在確率変数 z を導入することで、
x2 ∣ zz∼InvGamma(1/2,1/z)∼InvGamma(1/2,1/γ2)
これを用いると、τ,λj にそれぞれ対応する補助変数 ξ,νj を用意して、
馬蹄分布の逆ガンマ表現
βj ∣ σ2,τ,λjτ2 ∣ ξξλj2 ∣ νjνj∼N(0,σ2τ2λj2)∼InvGamma(1/2,1/ξ)∼InvGamma(1/2,1)∼InvGamma(1/2,1/νj)∼InvGamma(1/2,1)
という階層表現を得ることができます。σ2 の事前分布も逆ガンマ分布を使えば、馬蹄分布をすべて逆ガンマ分布で表現できたことになります。正規分布の分散パラメータに対応する共役事前分布は逆ガンマ分布ですから、このように構成した馬蹄分布は事後分布の一部もまた逆ガンマ分布で表現できます。
- 縮小事前分布、特に馬蹄分布に関する導入を参考にしました。
また、サンプルコードや数学的補足は一部 ChatGPT から生成しました。
- T. Park and G. Casella, The Bayesian Lasso, J. Am. Stat. Assoc., 103, 681–686 (2008).
- C. M. Carvalho et al., Handling Sparsity via the Horseshoe, Proc. Mach. Learn. Res. (PMLR), 5, 73–80 (2009).
- C. M. Carvalho, J. G. Scott. The horseshoe estimator for sparse signals, Biometrika, 97, 465–480 (2010).
- E. Makalic and D. F. Schmidt, A simple sampler for the horseshoe estimator, IEEE Signal Process. Lett., 23, 179–182 (2016).

